#
Advanced Parallelization(AP)
#
What is Advanced Parallelization?
The MoAI Platform's Advanced Parallelization (AP) is the automatic model optimization and distributed parallel processing feature. Typically, ML engineers go through numerous trial and error processes to optimize model parallelization during training of large-scale models. They experiment with various parallelization techniques, considering the memory size of the GPU in use, measure performance for different option combinations available in each technique, and determine optimized environment variables. This is a very laborious task that can take skilled machine learning developers from weeks to months.
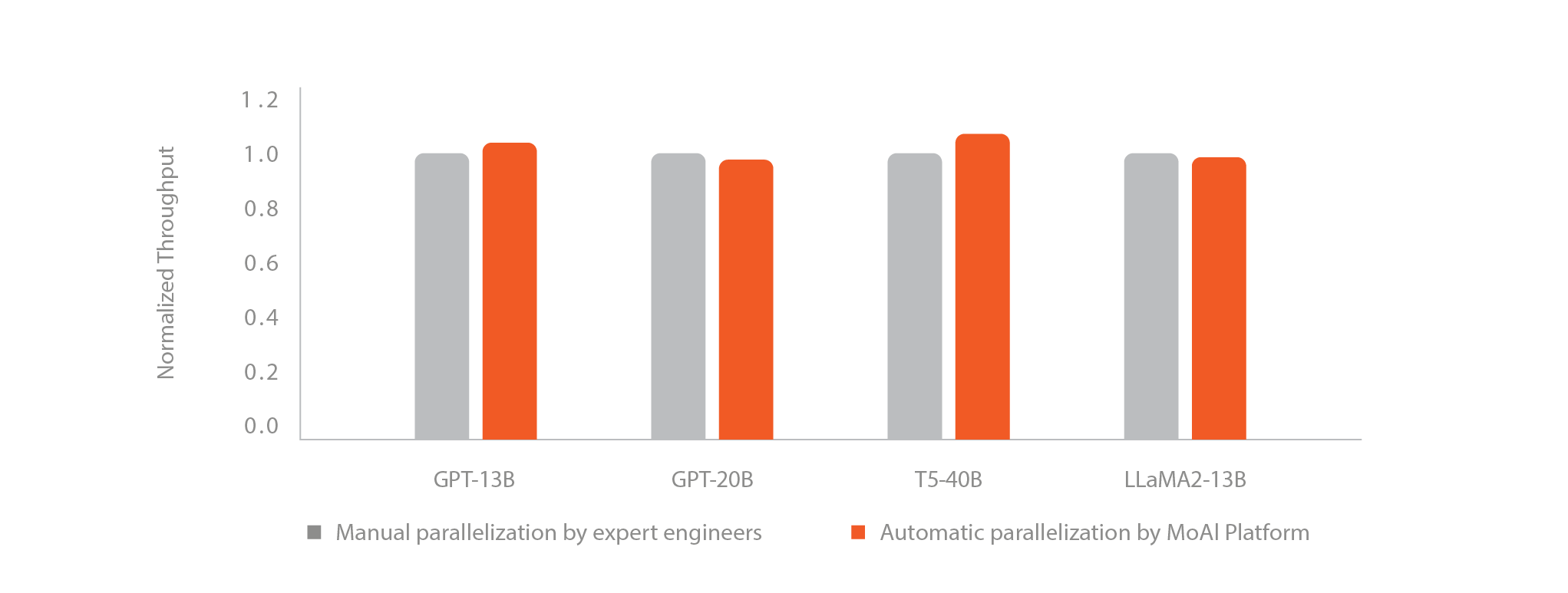
With the AP feature of the MoAI Platform, complex parallel processing and model optimization tasks can be automatically performed with just a single line of code, dramatically reducing the time and effort involved in training.
#
💡 Why is parallelization crucial?
As a simple example, let's calculate how much GPU memory is required to train the Llama2 13B model.
The Llama2 13B model contains approximately 13 billion parameters. The memory size required to load the model, depending on the FP16 data format, is approximately 25GB. A minimum of 100-150GB of memory is required for training components such as the optimizer and gradients. Therefore, training is impossible with just the memory capacity of a typical single GPU (80-128GB). This is why GPU parallel processing is essential for model training.
For example, when using FSDP (Fully Sharded Data Parallel) or DeepSpeed, developers must manually adjust various parallelization settings. In this case, the following parameters must be carefully adjusted:
- Parameter Sharding: FSDP requires specifying how to shard model parameters across GPUs. Incorrect settings can result in suboptimal performance or memory overflow errors.
- Optimizer Stat Sharding: Both FSDP and DeepSpeed require sharding the optimizer state for efficient memory usage and communication overhead, which entails complex configurations.
- Activation Checkpointing: Activation checkpointing may need to be activated to save memory, balancing additional computation overhead for saving memory and recalculating activations during backpropagation.
Users can focus on the goal of model training rather than the time-consuming procedure of configuring parallelization settings. With a single line of code below, the platform automatically handles the complexities of parallelization operations to assure optimal performance.
import torch
...
torch.moreh.option.enable_advanced_parallelization()
model = AutoModelForCausalLM(...) As a result, when training large models, users can easily obtain optimal parameters and environment variable combinations for parallelization techniques such as Data Parallelism or Pipeline Parallelism.