#
Advanced Parallelization(AP)
#
Advanced Parallelization(AP) 이란?
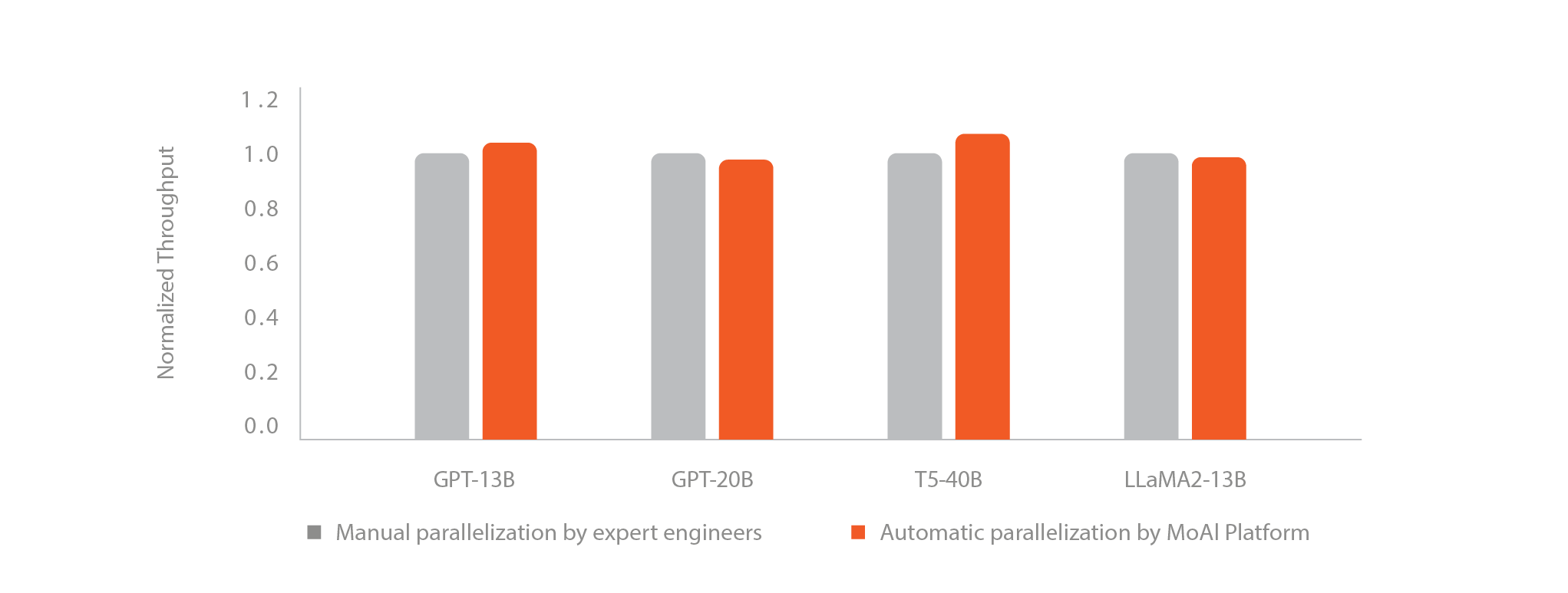
Advanced Parallelization(AP)은 MoAI Platform에서 제공하는 자동 모델 최적화 및 분산 병렬처리 기능입니다. 일반적으로 ML 엔지니어는 거대 모델 학습 시 모델 병렬화를 최적화하기 위해 수많은 시행착오를 겪습니다. 사용 중인 GPU의 메모리 크기를 고려해 여러 병렬화 기법을 직접 적용해 보고, 각 기법에서 활용할 수 있는 옵션 조합들에 대해 성능을 측정해 최적화된 환경 변수를 결정해야 합니다. 이는 숙련된 머신러닝 개발자가 작업하더라도 몇 주에서 몇 달까지 걸릴 수 있는 매우 고된 작업입니다.
MoAI Platform의 AP 기능을 이용하면, 단 한 줄의 코드 추가만으로 복잡한 병렬 처리 및 모델 최적화 작업을 자동으로 수행해 학습에 소요되는 시간과 노력을 획기적으로 줄일 수 있습니다.
#
병렬화가 반드시 필요한 이유는 무엇일까요?
간단한 예시로 Llama2 13B 모델을 학습할 때 필요한 GPU 메모리를 계산해 보겠습니다.
Llama2 13B 모델의 파라미터 수는 약 130억 개 입니다. 모델을 로드하는 데 필요한 메모리 크기를 FP16 데이터 타입을 기준으로 계산해보면 약 25 GB입니다. 학습에 필요한 optimizer, gradients 등까지 포함하면 최소 100GB에서 150GB의 메모리가 필요합니다. 따라서 보통의 단일 GPU가 보유한 메모리 크기(80 - 128GB)만으로는 학습이 불가능합니다. 이 부분이 모델 학습에 GPU 병렬 처리가 필수적인 이유입니다.
예를 들어, FSDP(Fully Sharded Data Parallel)나 DeepSpeed를 사용할 때, 개발자는 다양한 병렬화 설정을 수동으로 조정해야 하는 어려움을 겪습니다. 이 때 다음과 같은 매개변수를 신중하게 조정해야 합니다:
- 파라미터 분할: FSDP는 모델 파라미터를 GPU 간에 어떻게 분할할지 지정해야 합니다. 설정이 잘못되면 최적의 성능을 발휘하지 못하거나 메모리 초과 오류가 발생할 수 있습니다.
- 옵티마이저 상태 분할: FSDP와 DeepSpeed 모두 효과적인 메모리 사용과 통신 오버헤드를 위해 옵티마이저 상태를 분할해야 하며, 이는 복잡한 설정을 필요로 합니다.
- 액티베이션 체크포인팅: 메모리를 절약하기 위해 액티베이션 체크포인팅을 활성화가 요구될 수도 있으며, 더 나아가 메모리 절약과 역전파 시 액티베이션을 재계산하는 추가 계산 오버헤드 간의 균형을 맞춰야 합니다.
반면에, MoAI Platform의 AP 기능을 사용하면 사용자는 복잡한 병렬화 작업에 들이던 시간과 노력을 절약하여 다른 중요한 작업에 집중할 수 있습니다. 단 한 줄의 코드만 추가만으로, 플랫폼이 병렬화 작업의 복잡한 부분을 자동으로 처리하여 최적의 성능을 보장합니다.
import torch
...
torch.moreh.option.enable_advanced_parallelization()
model = AutoModelForCausalLM(...) MoAI Platform의 AP 기능을 사용하면 사용자는 병렬화 설정을 구성하는 번거로운 작업 대신 모델학습이라는 목표에 집중할 수 있습니다.
따라서 사용자는 거대 모델 훈련시 필요한 Data Parallelism이나 Pipeline Parallelism과 같은 병렬화 기법의 최적 매개변수와 환경 변수 조합을 간단히 얻을 수 있습니다.