#
Tag: tutorial
See all tags.
This tutorial guides you on fine-tuning the open-source Mistral 7B model on the MoAI Platform.

Preparing the PyTorch script execution environment on the MoAI Platform is similar to doing so on a typical GPU server.
Once you have prepared all the training data, let's delve into the contents of the train_mistral.py script to execute the actual fine-tuning process.
Now, we will train the model through the following process.
Running the train_mistral.py script, as in the previous section, will save the resulting model in the
Let's rerun the fine-tuning task with a different number of GPUs.
From this tutorial, we have seen how to fine-tune the Mistral 7B model on the MoAI Platform.
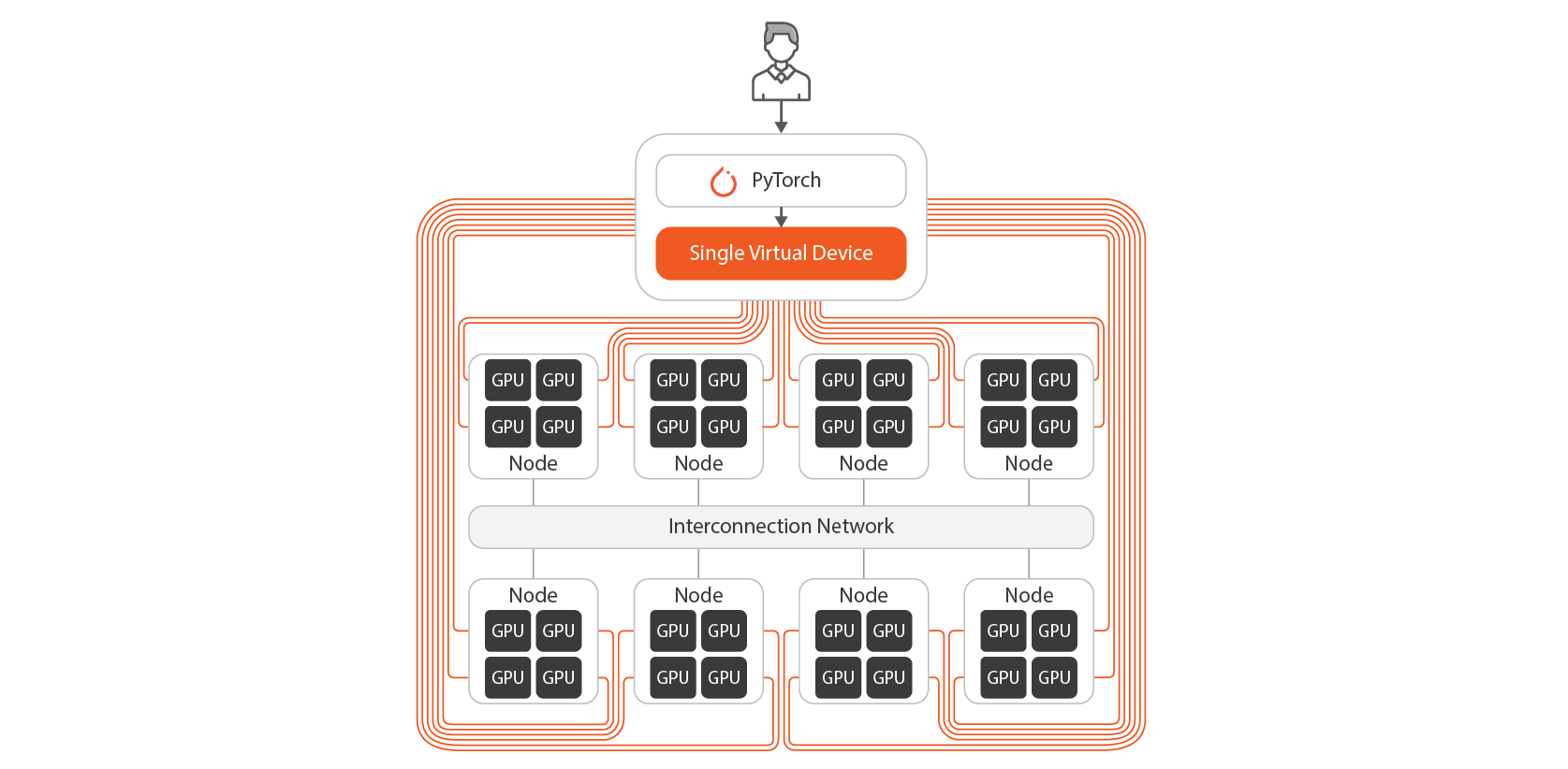
This tutorial introduces how to fine-tune the open-source LLama3-70B model using the MoAI Platform.
To fine-tune the Llama3 70B model, you must use multiple GPUs and implement parallelization techniques such as Tensor Parallelism, Pipeline...

For a smooth tutorial experience, the following specifications are recommended:
Now, we will actually execute the fine-tuning process.
We have now explored the process of fine-tuning the Llama3-70b model on the MoAI Platform.
This tutorial introduces an example of fine-tuning the open-source Baichuan2-13B model on the MoAI Platform.
Preparing the PyTorch script execution environment on the MoAI Platform is similar to doing so on a typical GPU server.
If you've prepared all the training data, let's now take a look at the contents of train_baichuan2.py
Now, we will train the model through the following process.
Similar to the previous chapter, when you execute the train_baichuan2_13b.py script, the resulting model will be saved in the
Let's rerun the fine-tuning task with a different number of GPUs.
So far, we've explored the process of fine-tuning the Baichuan2 13B model, which is publicly available on Hugging Face, using the MoAI Platform.
This tutorial introduces an example of fine-tuning the open-source Qwen2.5 7B model on the MoAI Platform.
Preparing the PyTorch script execution environment on the MoAI Platform is similar to doing so on a typical GPU server.
If you've prepared all the training data, let's now take a look at the train_qwen.py script to actually run the fine-tuning process.
Now, we will train the model through the following process.
Running the train_qwen.py script, as in the previous chapter, will save the resulting model in the qwen_code_generation
Let's rerun the fine-tuning task with a different number of GPUs.
So far, we've explored the process of fine-tuning the Qwen2.5 7B model on the MoAI Platform.
Please obtain a container or virtual machine on the MoAI Platform from your infrastructure provider and follow the instructions to connect via SSH.
MNIST on MoAI Platform
This tutorial introduces an example of fine-tuning the open-source Llama3-8B model on the MoAI Platform.

Setting up the PyTorch execution environment on the MoAI Platform is similar to setting it up on a typical GPU server.
Once you have prepared all the training data, let's take a look at the contents of the train_llama3.py
Now, we will actually execute the fine-tuning process.
When you execute the train_llama3.py script as in the previous section, the resulting model will be saved in the
Let's rerun the fine-tuning task with a different number of GPUs.
From this tutorial, we have seen how to fine-tune Llama3 8B on the MoAI Platform.