#
GPU Virtualization: MoAI Accelerator
The MoAI Platform virtualizes large GPU clusters, consisting of dozens or hundreds of GPU nodes, into a single accelerator called the MoAI Accelerator. This allows users to design and train models as if they are using a single GPU, without worrying about model parallelization or manually configuring cluster environments.
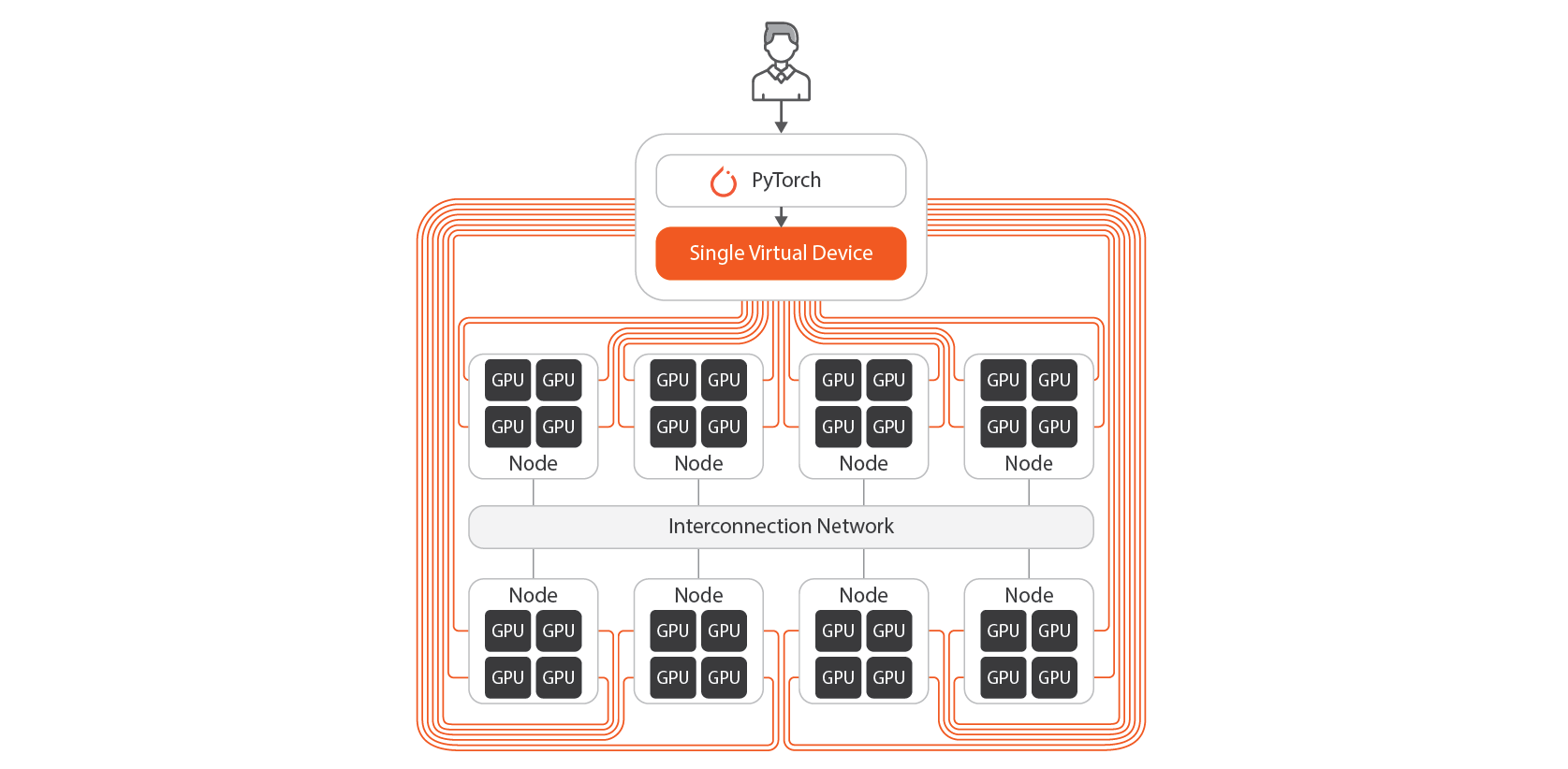
You can check the MoAI Accelerator status by entering the moreh-smi command in the terminal.
$ moreh-smi
+-----------------------------------------------------------------------------------------------------+
| Current Version: 24.5.0 Latest Version: 24.5.0 |
+-----------------------------------------------------------------------------------------------------+
| Device | Name | Model | Memory Usage | Total Memory | Utilization |
+=====================================================================================================+
| 0 | MoAI Accelerator | 4xLarge.2048GB | - | - | - |
+-----------------------------------------------------------------------------------------------------+The output shows that the user is utilizing a single accelerator with 2048 GB of memory. However, in reality, it consists of 4 nodes, each with 4 GPUs.
Let's verify if the MoAI Accelerator is recognized correctly in PyTorch, one of the most widely used deep learning frameworks. Using the cuda API in the Python interpreter, we can see that PyTorch recognizes the MoAI Accelerator as a single device.
$ python
Python 3.8.19 (default)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.cuda.device_count()
1An important point to note is that there are no physical GPUs in the user's environment. When the user attempts to use GPU accelerators through APIs like cuda in deep learning frameworks such as PyTorch, the MoAI Platform automatically allocates GPU cluster resources.
#
Dynamic GPU Allocation on the MoAI Platform
The MoAI Platform dynamically handles GPU allocation at the process level. This ensures that users efficiently receive physical GPU allocations while training and inferencing models using frameworks like PyTorch. It also provides flexibility, allowing users to select and adjust the number of GPUs from various pre-defined MoAI Accelerator flavors as needed.
In contrast, traditional cloud platforms typically allocate physical GPUs statically from the moment an instance is created. If users wish to change the number of GPUs or stop using them, they need to delete the existing instance or terminate the container and restart it. The MoAI Platform's dynamic allocation significantly reduces this inconvenience.
Let's go through a simple example of changing the MoAI Accelerator flavor.
First, check the current MoAI Accelerator in use by entering the moreh-smi command in the terminal.
$ moreh-smi
+---------------------------------------------------------------------------------------------------+
| Current Version: 24.5.0 Latest Version: 24.5.0 |
+---------------------------------------------------------------------------------------------------+
| Device | Name | Model | Memory Usage | Total Memory | Utilization |
+===================================================================================================+
| * 0 | MoAI Accelerator | xLarge.512GB | - | - | - |
+---------------------------------------------------------------------------------------------------+You can see that the current flavor of the MoAI Accelerator being used is
xLarge.512GB
. If you need to train a larger model or want to use more GPUs to speed up training, you can easily switch the flavor by entering the moreh-switch-model command.
$ moreh-switch-model
Current MoAI Accelerator: xLarge.512GB
1. Small.64GB
2. Medium.128GB
3. Large.256GB
4. xLarge.512GB *
5. 1.5xLarge.768GB
6. 2xLarge.1024GB
7. 3xLarge.1536GB
8. 4xLarge.2048GB
9. 6xLarge.3072GB
10. 8xLarge.4096GB
11. 12xLarge.6144GB
12. 24xLarge.12288GB
13. 48xLarge.24576GB
Selection (1-13, q, Q): 8
The MoAI Accelerator model is successfully switched to "4xLarge.2048GB".
1. Small.64GB
2. Medium.128GB
3. Large.256GB
4. xLarge.512GB
5. 1.5xLarge.768GB
6. 2xLarge.1024GB
7. 3xLarge.1536GB
8. 4xLarge.2048GB *
9. 6xLarge.3072GB
10. 8xLarge.4096GB
11. 12xLarge.6144GB
12. 24xLarge.12288GB
13. 48xLarge.24576GB
Selection (1-13, q, Q):
qAfter entering the moreh-smi command again to check the current MoAI Accelerator flavor, you can see it has been successfully changed to
4xLarge.2048GB
.
$ moreh-smi
+-----------------------------------------------------------------------------------------------------+
| Current Version: 24.5.0 Latest Version: 24.5.0 |
+-----------------------------------------------------------------------------------------------------+
| Device | Name | Model | Memory Usage | Total Memory | Utilization |
+=====================================================================================================+
| * 0 | MoAI Accelerator | 4xLarge.2048GB | - | - | - |
+-----------------------------------------------------------------------------------------------------+
#
Conclusion
The MoAI Platform simplifies the complexity of multi-node GPU clusters through virtualization technology known as the MoAI Accelerator. It provides users with a powerful yet flexible computing environment. By allowing users to adjust model size and the number of GPUs without complex settings and management tasks, it enables efficient resource utilization. Use the MoAI Accelerator on the MoAI Platform to design and train deep learning models quickly and efficiently.