#
태그: tutorial
모두 보기 태그.
이 튜토리얼은 Llama2, Mistral 등의 대형 언어 모델을 fine-tuning 하고자 하는 모든 분들을 위한 것입니다. MoAI 플랫폼을 사용하여 아래 대형 언어 모델들을 미세 조정하는 과정을 안내합니다.
이 튜토리얼은 MoAI Platform에서 오픈 소스 Llama3-8b 모델을 fine-tuning하는 예시를 소개합니다. 튜토리얼을 통해 아래와 같은 MoAI Platform이 제공하는 여러 기능을 체험하며, AMD GPU 클러스터를 사용하는 방법을 익힐 수 있습니다.

MoAI Platform에서 PyTorch 스크립트 실행 환경을 준비하는 것은 일반적인 GPU 서버에서와 크게 다르지 않습니다. 단, 튜토리얼 진행을 위해 아래의 사양들이 권장됩니다.
학습 데이터를 모두 준비하셨다면 다음으로는 실제 fine-tuning 과정을 실행할 train_llama3.py 스크립트의 내용에 대해 살펴 보겠습니다.
이제 실제로 fine tuning을 실행해 보겠습니다.
앞 장과 같이 train_llama3.py 스크립트를 실행하면 결과 모델이 llama3_summarization 디렉토리에 저장됩니다. 이는 순수한 PyTorch 모델 파라미터 파일로 MoAI Platform이 아닌 일반 GPU 서버에서도 100% 호환됩니다.
앞과 동일한 fine-tuning 작업을 GPU 개수를 바꾸어 다시 실행해 보겠습니다. MoAI Platform은 GPU 자원을 단일 가속기로 추상화하여 제공하며 자동으로 병렬 처리를 수행합니다.
지금까지 MoAI Platform에서 Llama3 8B 를 fine-tuning하는 과정을 살펴 보았습니다. Llama 와 같은 오픈 소스 LLM은 요약, 질의 응답 등 다양한 태스크에 활용할 수 있습니다.
이 튜토리얼은 MoAI Platform에서 오픈 소스 LLama3-70B 모델을 fine-tuning하는 예시를 소개합니다.
Llama3 70B 모델 전체를 파인튜닝하기 위해서는 필수적으로 다중 GPU를 사용해야 하며, 텐서 병렬화(Tensor Parallelism), 파이프라인 병렬화(Pipeline Parallelism), 데이터 병렬화(Data Parallelism) 등의 병렬화를...

원활한 튜토리얼 진행을 위해 아래의 사양들이 권장됩니다.
이제 실제로 fine tuning을 실행해 보겠습니다.
지금까지 MoAI Platform에서 Llama3-70b 모델을 fine-tuning하는 과정을 살펴 보았습니다. MoAI 플랫폼을 사용한다면 여러분이 1개, 4개, 100개 등 모든 개수의 GPU를 코드 변경 없이 손쉽게 설정할 수 있습니다.
이 튜토리얼은 MoAI Platform에서 오픈 소스 Mistral 7B 모델을 fine-tuning하는 예시를 소개합니다.

MoAI Platform에서 PyTorch 스크립트 실행 환경을 준비하는 것은 일반적인 GPU 서버에서와 크게 다르지 않습니다. 단, 튜토리얼 진행을 위해 아래의 사양들이 권장됩니다.
학습 데이터를 모두 준비하셨다면 다음으로는 실제 fine-tuning 과정을 실행할 train_mistral.py 스크립트의 내용을 살펴 보겠습니다. 이번 단계에서는 MoAI Platform은 pytorch와의 완전한 호환성으로 학습 코드가 일반적인 nvidia...
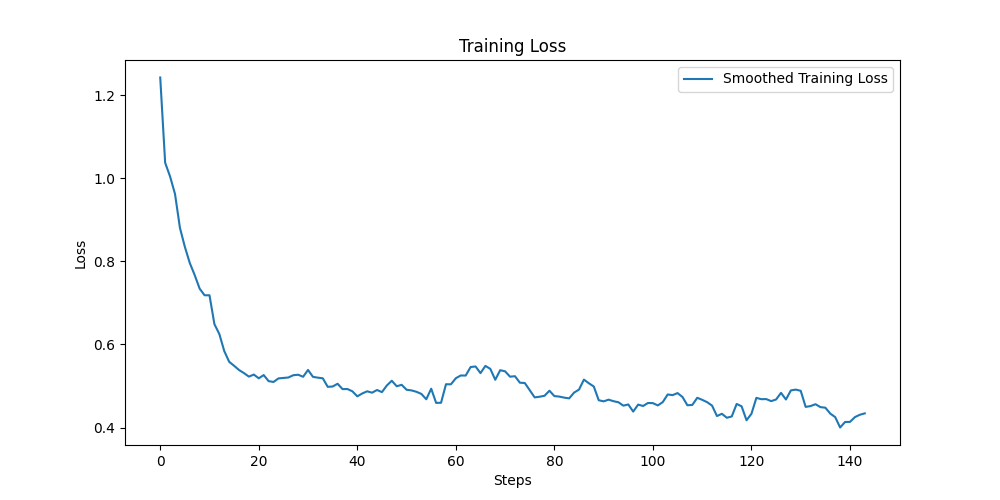
이제 실제로 fine tuning을 실행해 보겠습니다.
앞 장과 같이 train_mistral.py 스크립트를 실행하면 결과 모델이 mistral_code_generation 디렉터리에 저장됩니다. 이는 순수한 PyTorch 모델 파라미터 파일로 MoAI Platform이 아닌 일반 GPU 서버에서도 100% 호환됩니다.
앞과 동일한 fine-tuning 작업을 GPU 개수를 바꾸어 다시 실행해 보겠습니다. GPU 개수를 변경하여 다시 실행해 보겠습니다. MoAI Platform은 GPU 자원을 단일 가속기로 추상화하여 제공하므로 자동으로 병렬 처리를 수행합니다.
지금까지 MoAI Platform에서 Mistral 7B 모델을 fine-tuning하는 과정을 살펴 보았습니다. MoAI Platform을 사용하면 기존의 학습 코드를 그대로 사용하면서
이 튜토리얼은 MoAI Platform에서 Hugging Face 에 오픈소스로 공개된 GPT 기반의 모델을 fine-tuning하는 예시를 소개합니다.
MoAI Platform에서 PyTorch 스크립트 실행 환경을 준비하는 것은 일반적인 GPU 서버에서와 크게 다르지 않습니다. 단, 튜토리얼 진행을 위해 아래의 사양들이 권장됩니다:
학습 데이터를 모두 준비하셨다면 다음으로는 실제 fine-tuning 과정을 실행할 train_gpt.py 스크립트의 내용을 살펴 보겠습니다. 이번 단계에서는 MoAI Platform은 pytorch와의 완전한 호환성으로 학습 코드가 일반적인 nvidia gpu를...
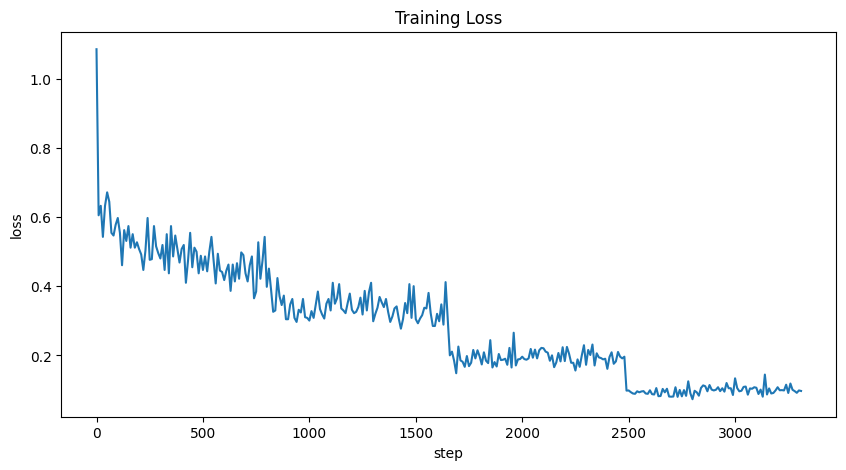
이제 실제로 fine tuning을 실행해 보겠습니다.
앞 장과 같이 train_gpt.py 스크립트를 실행하면 결과 모델이 code_generation 디렉토리에 저장됩니다. 이는 순수한 PyTorch 모델 파라미터 파일로 MoAI Platform이 아닌 일반 GPU 서버에서도 100% 호환됩니다.
앞과 동일한 fine-tuning 작업을 GPU 개수를 바꾸어 다시 실행해 보겠습니다. MoAI Platform은 GPU 자원을 단일 가속기로 추상화하여 제공하며 자동으로 병렬 처리를 수행합니다.
지금까지 MoAI Platform에서 HuggingFace에 공개된 GPT 기반 모델을 fine-tuning하는 과정을 살펴 보았습니다. MoAI Platform을 사용하면 기존의 학습 코드를 그대로 사용하면서
이 튜토리얼은 MoAI Platform에서 오픈 소스 Qwen1.5 7B 모델을 fine-tuning 하는 예시를 소개합니다.
MoAI Platform에서 PyTorch 스크립트 실행 환경을 준비하는 것은 일반적인 GPU 서버에서와 크게 다르지 않습니다. 단, 튜토리얼 진행을 위해 아래의 사양들이 권장됩니다.
학습 데이터를 모두 준비하셨다면 다음으로는 실제 fine-tuning 과정을 실행할 train_qwen.py 스크립트의 내용에 대해 살펴 보겠습니다.
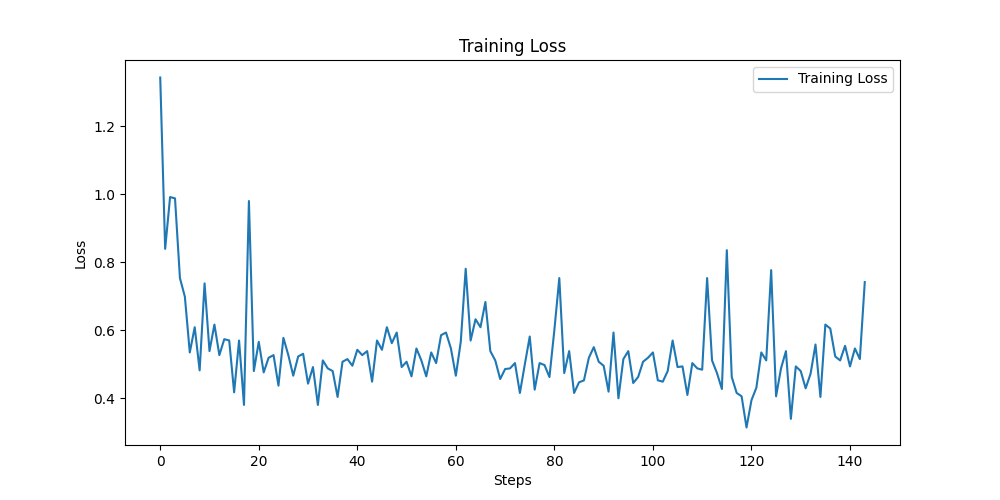
이제 실제로 fine tuning을 실행해 보겠습니다.
앞 장과 같이 train_qwen.py 스크립트를 실행하면 결과 모델이 qwen_code_generation 디렉터리에 저장됩니다. 이는 순수한 PyTorch 모델 파라미터 파일로, MoAI Platform이 아닌 일반 GPU 서버에서도 완벽히 호환됩니다.
앞과 동일한 fine tuning 작업을 GPU 개수를 바꾸어 다시 실행해 보겠습니다. MoAI Platform은 GPU 자원을 단일 가속기로 추상화하여 제공하며 자동으로 병렬 처리를 수행합니다.
지금까지 MoAI Platform에서 Qwen1.5 7B 모델을 fine-tuning하는 과정을 살펴 보았습니다. MoAI Platform을 사용하면 기존의 학습 코드를 그대로 사용하면서
이 튜토리얼은 MoAI Platform에서 오픈 소스 Baichuan2 13B 모델을 fine-tuning하는 예시를 소개합니다.
MoAI Platform에서 PyTorch 스크립트 실행 환경을 준비하는 것은 일반적인 GPU 서버에서와 크게 다르지 않습니다. 단, 튜토리얼 진행을 위해 아래의 사양들이 권장됩니다:
학습 데이터를 모두 준비하셨다면 다음으로는 실제 fine-tuning 과정을 실행할 train_baichuan2_13b.py 스크립트의 내용을 살펴 보겠습니다. 이번 단계에서는 MoAI Platform은 pytorch와의 완전한 호환성으로 학습 코드가 일반적인...
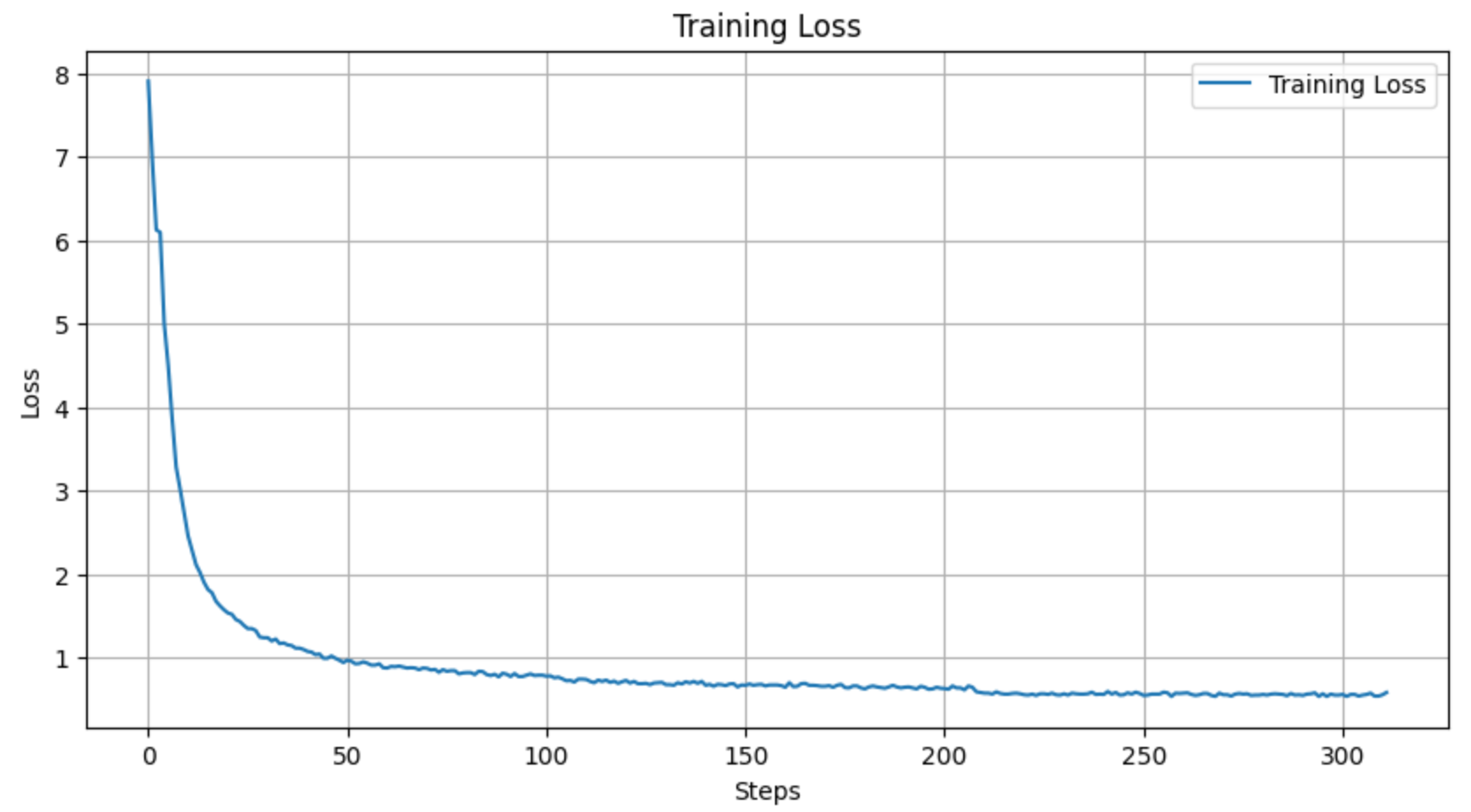
이제 실제로 fine tuning을 실행해 보겠습니다.
앞 장과 같이 train_baichuan2_13b.py 스크립트를 실행하면 결과 모델이 baichuan_code_generation 디렉토리에 저장됩니다.
앞과 동일한 fine-tuning 작업을 GPU 개수를 바꾸어 다시 실행해 보겠습니다. MoAI Platform은 GPU 자원을 단일 가속기로 추상화하여 제공하며 자동으로 병렬 처리를 수행합니다.
지금까지 MoAI Platform에서 HuggingFace에 공개된 Baichuan2 13B 모델을 fine-tuning하는 과정을 살펴 보았습니다.
이 튜토리얼은 MoAI Platform에서 오픈 소스 Llama2 13B 을 fine-tuning하는 예시를 소개합니다. 튜토리얼을 통해 아래와 같은 MoAI Platform이 제공하는 여러 기능을 체험하며, AMD GPU 클러스터를 사용하는 방법을 익힐 수 있습니다.

MoAI Platform에서 PyTorch 스크립트 실행 환경을 준비하는 것은 일반적인 GPU 서버에서와 크게 다르지 않습니다. 단, 튜토리얼 진행을 위해 아래의 사양들이 권장됩니다:
학습 데이터를 모두 준비하셨다면 다음으로는 실제 fine-tuning 과정을 실행할 train_llama2.py 스크립트의 내용에 대해 살펴보겠습니다.
이제 실제로 fine tuning을 실행해 보겠습니다.
앞 장과 같이 train_llama2.py 스크립트를 실행하면 결과 모델이 llama2_summarization 디렉토리에 저장됩니다. 이는 순수한 PyTorch 모델 파라미터 파일로 MoAI Platform이 아닌 일반 GPU 서버에서도 완벽하게 호환됩니다.
앞과 동일한 fine-tuning 작업을 GPU 개수를 바꾸어 다시 실행해 보겠습니다. MoAI Platform은 GPU 자원을 단일 가속기로 추상화하여 제공하며 자동으로 병렬 처리를 수행합니다.
지금까지 MoAI 플랫폼에서 Llama2 13B 로 텍스트 요약 작업을 할 때 fine-tuning 하는 과정을 살펴보았습니다. Llama와 같은 오픈 소스 대형 언어 모델(LLM)은 요약, 질문 답변 등 다양한 자연어 처리 작업에 활용될 수 있습니다.